
By Brian Lucas
“Facts are stubborn things; whatever may be our wishes, our inclinations, or the dictates of our passions, they cannot alter the state of facts and evidence.” – JOHN ADAMS
What can you do when someone honestly doesn’t see the real underlying differences between agile and waterfall concepts? What do you do when you have tried all of your standard explanations and you both still can’t see things from a common perspective? The answer, of course, is – adapt! If what you are saying isn’t convincing; then try something else. Inject something small that’s different into the dialog and see what impact it has. Facts are notoriously unrelenting and will be acknowledged by any reasonable person. Never let your emotional frustration provide an answer that should have come from your dispassionate logic. You need to understand your subject and respect the person with whom you are dialoging. You will find that articulating proofs of this nature will actually strengthen your knowledge; much like defending a doctoral thesis. So to prove that I practice what I preach; I am including the following email stream. It’s a dialog I am having with a very good person and friend of mine named Jim. He is both very intelligent and a phenomenal worker and just happens to be an agile “semi-skeptic”.
Jim: “So what is agile? Is it a methodology or a framework?”
Brian: “Agile is, in its deepest and most profound sense, a philosophy of intelligent adaptation to constantly acquired knowledge and changing circumstances. Agile is solely driven and measured by business success. Agile is not simply a development methodology. Ultimately, all aspects of the enterprise from strategic planning to the most atomic level tasks must embrace agile for optimal effect. People that are looking for a fixed methodology or a heavily controlled process for agile will always realize less benefit – if not experience downright failure. The key words here are adaptation and success.”
Jim: “I don’t know, I just see agile as waterfall with a twist just in smaller iterations.”
Brian: “It is unfortunate that you see agile as waterfall with a twist, since the agile concept is actually the antithesis of waterfall principles. I am sure your view will change over time and with exposure.”
Jim: “Both Agile and Waterfall, to me, seem to have a large number of small implementations vice one big one. Both establish a time box and ask “what can you do within this constraint?” I think that Agile compresses the time box and addresses one of the main problems with waterfall — when you are ready to deliver, the business or marketplace could have changed so much that it is no longer relevant. Waterfall puts the emphasis on documentation up front under the basis that it costs more to redesign and fix a solution than it does to build it correctly in the first place. Agile says it costs more to build an outdated solution. I think it also de-emphasizes (but does not eliminate) documentation – always a popular notion. (Whenever I get the urge to document, I lie down until it goes away…) Interestingly enough, when you Google “similarities between agile and waterfall methodologies” you find an article on the IBM website that describes Agile as “Waterfall 2.0”… As with all methodologies, neither is correct for every project and both will probably continue to have their place alongside the other myriad of methodologies.”
Brian: “Jim, I am sure you are aware that all-that-is-written-is-not-gold! Actually waterfall and agile are not similar in the way you might think. Waterfall does not normally embrace the concept of a time box except for gross purposes. Estimation techniques like function point analysis are based on having a detailed requirements document completed. Estimates are often not made before then.
Another big difference is that who is doing what and when changes dramatically between waterfall and agile. In waterfall methods, analysts create requirements up front, followed by designers who transmogrify that output into more documentation, followed by developers who further interpret that documentation into code and then add more documentation to the code, followed by testers that interpret all the previous documentation and create more documentation, followed by help writers who – guess what – and last but not least the implementers. This is a massive amount of documentation that is virtually never kept in sync and up-to-date and interpreting the written word always leads to confusion.
Putting that aside for now, in agile, a team does most of the activity together – not an individual. The team directly shares knowledge and gains a common understanding, first hand, rather than through documentation interpretation. The team, usually an analyst, a user, a developer, a tester and a UI designer, work together on user stories, acceptance criteria, UI design (usually wireframes) and test cases. When the developer actually starts coding, the need and the proposed solution are so well understood in a common contextual framework that miscues are rare. Even if they occur they are limited in scope to the duration of at most a single iteration and usually are caught in the daily scrums.
Furthermore, agile really concentrates effort on a single unit of work-in-process. This focus increases the efficiency of the effort and generally the quality of the results. But let’s move right on to methodology coexistence. The fact is waterfall is dying a not-so-slow-death. Agile beats waterfall by almost a 3 to 1 margin. Enterprises have abandoned waterfall in favor of agile according to a Forrester Global Developer Survey in 2009 and the disproportionality of the numbers is increasing all the time as you can see in the following figure: 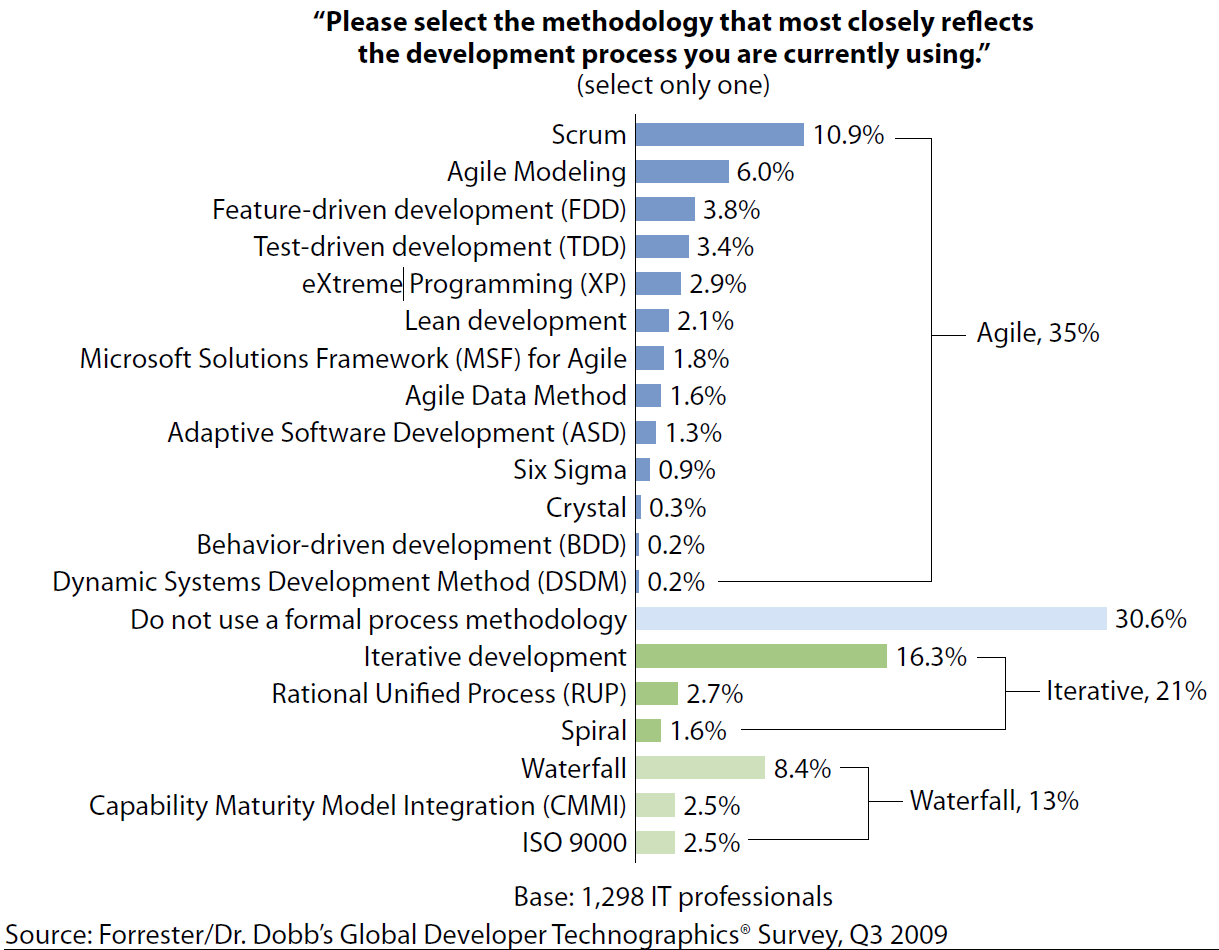
My last argument (for now) is that knowing you as I do, I believe you actually always operate and operated in an agile fashion and really don’t think in any other way. I have observed that some people, who are natural agilists, just like some people who are naturally object-oriented, can’t really conceive of another way of thinking. So I suspect that your view of waterfall is skewed by your own natural agile tendencies.“
Jim: “In ancient times – I’m thinking of the early 1990’s — I participated with a group of people to do an in-depth study of various methodologies. I came away from this with a belief that DATA is the key to it all. A company needs to know how profitable it is. No matter what company and what product you are talking about, the answer is the same. PROFIT = SELLING-PRICE – COST-TO-PRODUCE. It is the definition of these terms for the specific company that makes all the difference. The cost-to-produce may include all kinds of indirect things, for example – just to be a little silly about it – the cost of putting batteries in the automatic paper towel dispensers. If you don’t catch that with a robust design, over the course of the years this dollar leak will accumulate until a lot of money is missing and no one will know where it went. To make my point, I purposefully chose a silly example (unless of course your business is to replace batteries in paper towel dispensers.) But my feeling is that one of the shortcomings of Agile is a robust data design up front. It would seem to me that you would always be updating it as new data points are added. This issue is nothing new in the IT industry, but Agile makes it happen more often. More changes mean more problems means more disruption to my users. And what do I do with my 100K rows of sales data when a new “required” field is suddenly added??.”
Brian: “Jim, I agree with you that data is important it is one of the critical defining factors of a system. However, agile does not mean no data design; it merely means that you don’t spend a tremendous time up front attempting to figure out what your data design should be when you know the least amount about the solution.
I have seen a tendency in data modelers that like to work in a waterfall fashion to stuff in everything including the kitchen sink in their data models in an attempt to make them encompass even bizarre user circumstances. Just for fun I once did an inventory of data bases at a company I was consulting at to see how much data was in each field and furthermore did a database analysis to see how often it was accessed. Well I found that only about 50% of the structures had most of the data, but the real kicker was when I looked at the actual usage statistics. Sure enough – only 22% of the fields were accessed on a regular basis; 41% were accessed infrequently and 27% were virtually never accessed after original population. The Pareto Principle struck again.
Another direction I have seen is where modelers design an overabundance of abstraction into the data model. This pushes basic relational database management system (RDBMS) functions up into the application program layer. The resulting program code then ends up doing what a RDBMS was designed for which complicates the code and generally results in poor performance. With this approach there is also a marked lack of functionality in the application and the user ends up having to do a significantly greater amount of work per transaction. You mention disruption to your users – nothing is more disruptive to your users than a solution delivered late and with a bloated design that requires day in and day out more effort on the user’s part than is absolutely necessary.
From a data design perspective, I have been working on (in the last several years) a “functional engine design concept” for the data layer of agile developed systems. This builds robustness into the solution without sacrificing performance or ease of use. It enables customer driven extensibility within the domain of the solution. This means the RDBMS can do what it was designed for, program code can focus on business logic and the user gets to have things their way. Best of all, from an agile perspective, It can be introduced in an iterative fashion and grow virally into an existing system taking over a dysfunctional design in a piecemeal fashion. So to sum up, agile doesn’t mean no data design up front; it means a smarter data design that evolves as your knowledge of the solution increases.”
_____________________________________________________________________
James has taken over Jim’s skeptical side of the discussion. He is not the same person.
James: “Brian, I am glad you agree that data is an important and even critical defining factor of a system. The question in agile is where you start and how you proceed? In agile how do you go about identifying what data you need? Data modeling gives designers and developers a guide to analyzing the data needs of the system. This helps to make the development requirement more complete. In agile you must be always adding new data that you end up needing that you missed in your initial pass. This requires model changes and code rework.”
Brian:
“James, first of all let me welcome you to the forum and thank you for taking over Jim’s position. Let me deal with your arguments point by point.
- The question in agile is where you start and how you proceed?
Answer: You start identifying data in agile based of the functional needs of the user story. - In agile how do you go about identifying what data you need? Data modeling gives designers and developers a guide to analyzing the data needs of the system. This helps to make the development requirement more complete.
Answer: As you progress this thru wireframes, you actually get something very concrete to work with rather than having esoteric conversations with users about their data needs. I am sure you will have to admit that users can never guess all of their data needs off the top of their heads. It is when they actually start working with a solution that the needs become clearer. This is one of agile’s great advantages. - In agile you must be always adding new data that you end up needing that you missed in your initial pass. This requires model changes and code rework.”
Answer: If you take the life of an agile project and compare it to the life of a similar function sized non-agile one you will find that actual rework is less in the agile one. This is because most changes happen when there is less code and it is simpler. It also is a result of the fact that there is much less unneeded code developed in an agile project than a traditional one. This code can be as high as 80% of the code base and even though it is unneeded once created it still needs to be maintained.”

This is quite an interesting blog. I really like the format and the content is rich, informative and DIFFERENT! I especially like the very practical and pragmatic approach Mr. Lucas takes. He doesn’t spout a lot of theory and appears to have an incredible breath and depth of knowledge. I really like this conversation with his friend Jim even though they don’t agree he treats him with respect. That’s something I find very refreshing. I am going to follow this blog regularly. I hope he posts frequently. I like the writing style a lot to the point and without fluff, yet entertaining.
Thanks Derrik I have enjoyed this debate with Jim. I will endeavor to get him active in it again. -Brian
Nice post. Good arguments on both sides. I have been a Scrum skeptic, much more so than Jim. But I admit Brian’s arguments are convincing. I watched his webinar Is Agile a Fad or an Evolution it was probably the best I have ever seen. Where the heck has this guy been hiding. This was riduculously hard to find though. You need to promote this better. It makes no sense to blog this well if it doesn’t reach a larger audience.
Thanks Paul! I am not a graphic arts specialist so the artwork I use is simple or non-existent. I try to focus on written content. However I am doing this in my own time and posting ever day or week is just not possible.
A very nice interchange between Brian and Jim. I am sorry it did not go farther than it did. I believe it would have been very instructive. This is a good blog. It has very solid posts! Great information! Wide variety of subjects! Its too bad the frequency of posts is low. I would think based on his writing Brian is someone who has enough knowledge to comment on a subject every day. I would love to see this interchange between Brian and Jim continue………
I will see if I can pest Jim enough to continue the debate. Thanks for reading.
I believe I speak for more than just myself when I say that I am sorry this stream came to such an abrupt end. I believe it showed a lot of promise. As a project manager with many years of experience, I for one am more of a doubter than Jim is about agile. Without solid planning, tight management, good coordination and adherence to standards and procedures; I don’t see how any moderate to large project in any business enterprise can be successful. I do appreciate Mr. Lucas’s remarks and respect his position. He is apparently an informed and experienced person. I also respect greatly his starting this stream. I believe it was a great idea to make this discussion amongst what seems to be good friends of different opinions public. I would strongly encourage Brian and Jim to continue their dialog. I think it would make a great webinar as well.
Matt – I believe that James will be taking over Jim’s side of the argument. I will await his first email. -Brian
Hey Brian, have you heard at all from your friend Jim after your last response? I have worked as a project manager for various large companies for over 25 years and been following your blog and found this a very interesting exchange. I believe agile has some applicability in tactical instances, but I do not think it applies as universally as it is hyped. Has Jim stopped posting? If so that’s a shame since I respected his opinion. I do also have to admit that you are a very strong advocate for agile and your blog is getting me reengaged in the agile philosophy again. Perhaps if Jim has ended his commentary, you will allow me to pick up this stream and argue the conservative side. Interested?
James, Jim (this could get confusing) is a very busy person literally a one man team. So posting or even responding to an email is a catch as catch can. I would enjoy any interchange on the merrits of agile so in the immortal words of Admiral Dewey, “You may fire when you are ready, Gridley!” -Brian
I see only one response from James here after he took over for Jim. Is this stream over?
No more are coming. I promise.
I’ll chime in with the others its a shame this dialog fizzled out.
I am going to disagree that this is one of the more interesting posts. I have worked as a software developer for the last 8 years exclusively on agile projects in C# using a Scrum or modified Scrum methodology. I really haven’t had the situation where I was confronted with anyone I had to convince about the merits of agile. The naysayers who didn’t get on board with agile were all on the outside looking in. More than a few ended up being canned. I would like to see more posts about prioritization and improving team velocity, rather than continue this old argument. No offense meant to either side.
Your voice has equal value! Thank you for expressing an oipinion.
Let me weigh in on this. With all respect to R.Braun, I would like to see this stream continue. Not all of us enjoy the position he is in where agile is a given. This post helps us answer objections. I would vote for it to continue.
James has taken over for Jim and emailed me his opening contention. I have to post it and do my response. I promise it will be soon.
Well researched, well thoughout, well written! WELL DONE!
Interesting exchange of ideas. I wish this was a longer stream and was podcast!
Please don’t let this exchange die!!!!!
Brian please don’t abandon this stream. It really helps us make the agile argument.
It not over until the _ _ _ lady sings!
I hope you continue this discussion I found it interesting since I am not convinced agile is the way to go.
Its a shame Brian you couldn’t convince Jim…
Jim in not unconvinced or convinced as of this stage.
Brian I did enjoy this exchange and I hope that you continue it as promised.
Brian please follow up on this stream as you promised!